
分库分表解决方案
前言
分库分表是企业解决数据量大、并发量大的常见手段。
分库 & 分表
这里简单对分库 & 分表的一些概念做一些解释,不过多赘述。
由于数据库的连接数是有限的,当读写的 QPS 时过高导致数据库连接不足时,就可以考虑分库,提供更多可用的数据库连接,提升系统并发度。
而当单表的数据量增大到一定规模时,查询性能一定会下降,可以通过将数据拆分到多张表,来减少单表数据量,从而提升查询速度。
所以,分库主要用于提升并发度、分表主要用于提升查询性能,分库分表也可以同时做。
在分库分表中,还涉及到如何拆分的问题?水平拆分还是垂直拆分。
一种比较好理解但不太正确的理解方式是水平拆分视为数据拆分,而垂直拆分理解为字段拆分。
举个例子:
- 水平拆分:order 拆分为 order_001、order_002、……
- 垂直拆分:order 拆分为订单明细表、订单主表、……
分片键的选择
所谓分片键,本质上就是由逻辑表路由到物理表的依据,分片键也是表中的一个字段。当查询条件带上分片键,就可以精准指向目标物理表,否则就需要扫描所有的物理表,造成读扩散。
所以,分片键的选择是至关重要的,除了一些特殊的情况,一般分片键的选择都要保证三点:
- 是查询频率较高的字段
- 可以将数据均匀分布
- 不能随着业务的变化而修改,否则数据的路由可能会发生变化
以常见的订单表为例,一般来说(抛开一些特殊的场景),可供选择的分片键包括买家 id、商家 id 以及订单 id。
首先商家 id 一般不会作为分片键,主要是为了避免大商家导致数据倾斜的问题,比如淘宝上的大商家可能会产生很多订单,如果以商家 id 作为分片键,就会导致分表数据不均匀。
而对于买家 id 来说,是不会出现数据倾斜的,因为一个买家不太可能把数据买倾斜了。
当然订单 id 作为分片键也是可以的,具体选择买家 id 还是订单 id 就看业务了,哪个查询的频率更高就用哪个。
如何支持查询
当我们选择订单 id 或者买家 id 作为分片键之后,如何支持其他维度的查询?
假定我们以买家 id 作为分片键,当根据买家 id 进行查询时,由于带上了分片键,因此可以直达目标物理表进行查询,但是如果要以订单 id 或者卖家 id 进行查询就会出现读扩散(没有分片键),除此之外,系统可能还需要支持一些复杂维度的聚合查询,比如报表分析等。
那么解决这些问题的方案也很简单,两个字,“冗余”。
全量冗余
一个简单但是费钱的方式是全量冗余。
将全量的订单数据再次按照商家 id、订单 id 作为分片键进行冗余,这些冗余的分表只提供查询功能,数据的变更由买家订单表准实时同步而来。
而对于一些复杂维度的聚合查询,就需要使用 ES 来支持了。
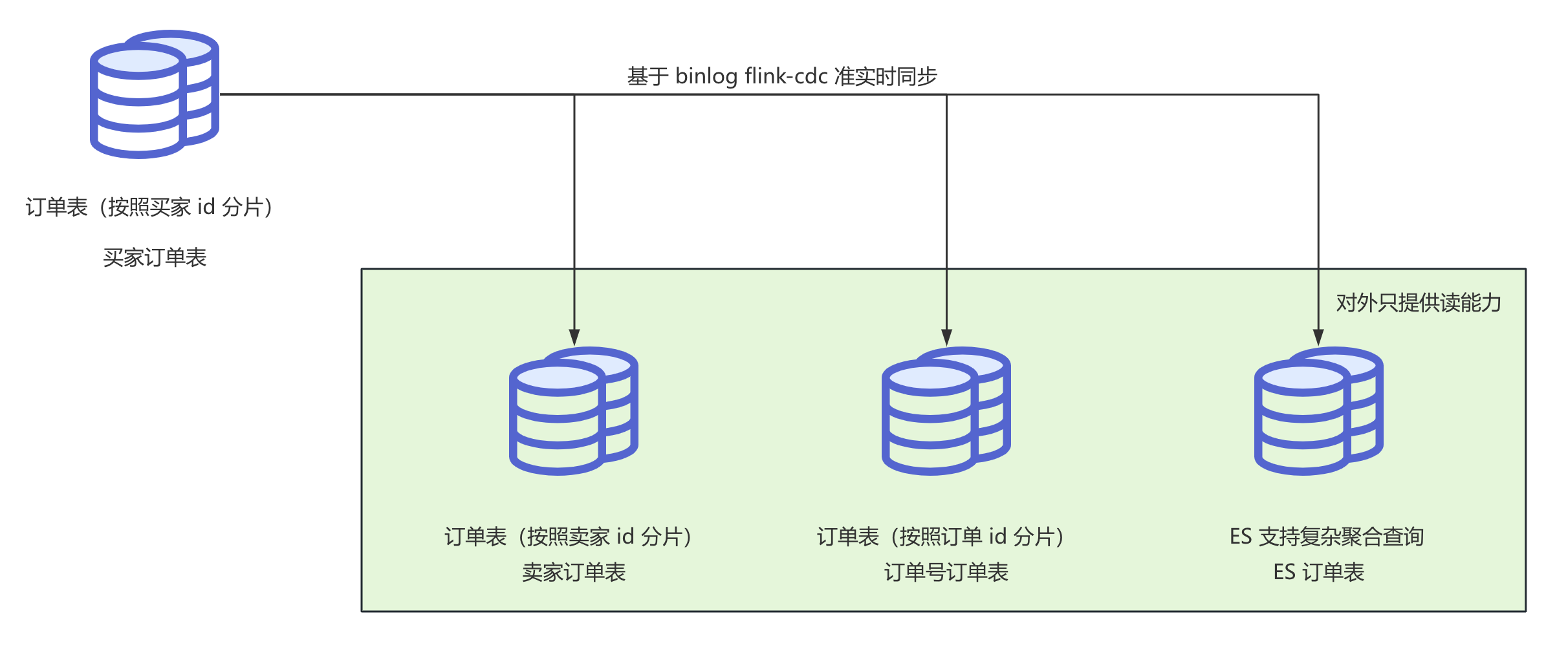
这里进行数据同步工具的选择有很多,比如 Canal、Flink CDC。
当然,这里同步出来一张卖家订单表,会不会又带来大卖家的数据倾斜问题?
首先,在业务层面的数据写入还是写入到买家订单表,这里已经处理好了事务相关的问题,所以理论上来说,进行准实时同步的性能是很高的,而且无需阻塞业务流程。
其次,大卖家一般是可以提前识别的,可以针对这些大卖家的数据进行二次分表,只需要设计好卖家订单表的分片算法即可。
最后,如果要基于卖家 id 或者订单 id 进行更新,最好的方法是先到卖家订单表或者订单号订单表查询出买家 id,然后根据买家 id 写到买家订单表,总之,业务层面的数据写入一定要写入到买家订单表。
全局二级索引 GSI
全量冗余可以提高最快的查询性能,但是毫无疑问,是非常浪费资源的,所以还有一种方式是使用全局二级索引。
全局二级索引的设计思想其实可以类比与 MySQL 的覆盖索引。
还是以上面的例子来说,我们额外维护两个分别以卖家 id 和订单 id 作为分片键的全局索引表,在全局索引表中维护了买家 id 的信息。
当基于卖家 id 查询时,就需要先在全局索引表中查询到卖家 id 对应的买家 id,然后再拿买家 id 去查询订单表。
这样做的优势在于,全局二级索引表占用的空间相较于订单表而言是非常少的,只是在查询时需要进行二次路由。
有一点时间换空间的味道。
另外,我们也可以在二级索引表里面冗余一些查询频率很高的字段来避免二次路由(回表),这是不是就是 MySQL 的覆盖索引的思想。
同样,如果是基于卖家 id 和订单号的更新,也是先通过二级索引表查询出买家 id,然后去做更新(只能这样做)
- 参考 全局二级索引(GSI)
基因分片
除了上面两种方式,还有一种基因法的实现。
说的通俗易懂点,就是将买家 id 的后 n 位冗余到订单 id,这样就可以按照买家 id 后 n 位作为路由到物理表的依据,买家 id 和订单 id 作为复合分片键。
在查询时,只要携带这两个字段中任意一个,我们都可以取其后 n 位路由到目标物理表。
当然,你也可以在生成订单 id 时直接冗余买家 id 的路由结果,本质上都是一样的。
比如,在 ShardingShpere 中,可以配置如下的复合分片算法:
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingAlgorithm;
import org.apache.shardingsphere.sharding.api.sharding.complex.ComplexKeysShardingValue;
import java.util.Collection;
import java.util.HashSet;
import java.util.Map;
import java.util.Properties;
public class BillComplexAlgorithm implements ComplexKeysShardingAlgorithm<Long> {
/**
* 分片算法下的配置
*/
private Properties prop;
private static final String USER_ID = "user_id";
private static final String BILL_ID = "bill_id";
@Override
public Collection<String> doSharding(Collection<String> availableTargetNames, ComplexKeysShardingValue<Long> complexKeysShardingValue) {
int shardingCount = availableTargetNames.size();
String logicTableName = complexKeysShardingValue.getLogicTableName();
Map<String, Collection<Long>> shardingMap = complexKeysShardingValue.getColumnNameAndShardingValuesMap();
Collection<String> result = new HashSet<>();
if (shardingMap == null) {
return result;
}
if (shardingMap.containsKey(USER_ID)) {
shardingMap.get(USER_ID).stream().findFirst().ifPresent(userId -> result.add(logicTableName + "_" + doRoute(userId, shardingCount)));
} else if (shardingMap.containsKey(BILL_ID)) {
shardingMap.get(BILL_ID).stream().findFirst().ifPresent(patientId -> result.add(logicTableName + "_" + doRoute(patientId, shardingCount)));
}
return result;
}
// 取后 6 位作为分片依据
private String doRoute(long shardingValue, int shardingCount) {
return String.valueOf(Long.valueOf(shardingValue % 100000).hashCode() % shardingCount);
}
@Override
public Properties getProps() {
return prop;
}
@Override
public void init(Properties properties) {
this.prop = properties;
}
}dataSources:
ds:
dataSourceClassName: com.zaxxer.hikari.HikariDataSource
driverClassName: com.mysql.cj.jdbc.Driver
jdbcUrl: jdbc:mysql://127.0.0.1:3306/test?useUnicode=true&characterEncoding=UTF-8&rewriteBatchedStatements=true&allowMultiQueries=true&serverTimezone=Asia/Shanghai
username: root
password: root
rules:
- !SHARDING
# 分片表
tables:
stc_bill_detail:
actualDataNodes: ds.bill_${0..3}
tableStrategy:
complex:
shardingColumns: bill_id,user_id
shardingAlgorithmName: bill_complex_algorithm
shardingAlgorithms:
bill_complex_algorithm:
type: CLASS_BASED
props:
algorithmClassName: org.hein.algo.BillComplexAlgorithm
strategy: complex
props:
sql-show: true当然,一般来说,订单 id 可以冗余买家 id,但是卖家 id 肯定是不能冗余买家 id 的,所以对于卖家 id 维度的查询,还是需要做同步冗余,要么是全量冗余,要么是全局二级索引冗余。
如何水平扩容
- 数据库容量到达瓶颈,需要进行水平扩容
- 出现了数据倾斜,需要重新设计分片算法
关键词: 2n 平滑扩容(TODO)