
缓存一致性
前言
对于一些高并发请求访问的数据,我们可以通过加入缓存(Redis)来提升用户访问的速度以及系统的性能,保护数据库实例不会因为大量的请求被击垮。
从本质上来说,缓存数据就是数据库数据的一个副本,由于缓存一般是在内存中,所以可以起到提升查询性能的作用。
既然缓存数据是数据库数据的副本,那么就一定会出现数据一致性问题。
比如在非并发场景下,由于写数据库和写缓存没办法保证原子性,所以可能会出现一个写成功一个写失败从而导致数据不一致的情况,而在并发场景下,数据一致性的问题就更多,也更复杂了。
所以这篇文章,我们就来聊一聊这个一致性问题。
加缓存的理解
我们先来说说,对加缓存的理解,因为加缓存不是那么简单的事,需要有一个方方面面的考虑。
首先,只有一些读写占比比较高的热点数据才适合放入缓存中,这里有两个关键词,「读写占比较高」以及「热点数据」。所谓读写占比较高,就是指读多写少,如果缓存数据是更新比较频繁的数据,就有可能你还没有读它,它就被更新了,这就失去了缓存的意义,还有就是如果查询的数据不是热点数据(查询频率比较高的数据),其实也是没有必要做缓存的。
其次,我们要考虑缓存加在哪里,在整个系统中,能够加缓存的地方其实是很多的,比如浏览器缓存、CDN 缓存、本地缓存、远端缓存等。
另外,我们还要考虑业务数据对一致性的要求,如果是对那些需要保证强一致的数据做缓存,那么势必要加锁来保证数据的强一致性,这其实就和我们加缓存的初衷违背了,因为加锁必然会导致性能的急剧降低,所以我们一般不会给那些要求强一致性的数据加缓存。
最后,对于几乎所有的缓存数据,我们也强烈要求要对缓存数据设置过期时间来作为极端情况下缓存和数据库数据始终无法达到最终一致性的兜底措施。
如何理解一致性
我们知道,在事务 ACID 特性中,也有一个一致性,这个一致性和我们这里所说的缓存一致性是不一样的。
你可以会想这里的缓存一致性是否是 CAP 中的 C,但实际在我看来并不是。
事务中的一致性强调数据库中的数据符合数据完整性约束,而 CAP 中的一致性是指访问分布式中的任意节点,必须要能够得到最近写的、一致的数据,这里更强调数据的强一致性。
所以缓存一致性既不是 ACID 中的 C,也不是 CAP 中的 C,它更强调弱一致性或者最终一致性。
数据一致性问题
首先对于数据的查询和新增,其实是不会有任何数据一致性问题的,所以主要还是需要考虑更新和删除的场景。
删除场景
我们先来说说数据库删除的场景。
如果缓存中没有数据,那么我们只需要删除数据库的数据即可,这是没有一致性问题的。
但如果缓存和数据库中都有数据,情况就变得复杂了,我们需要考虑先删缓存还是先删数据库。
先删除缓存,后删除数据库
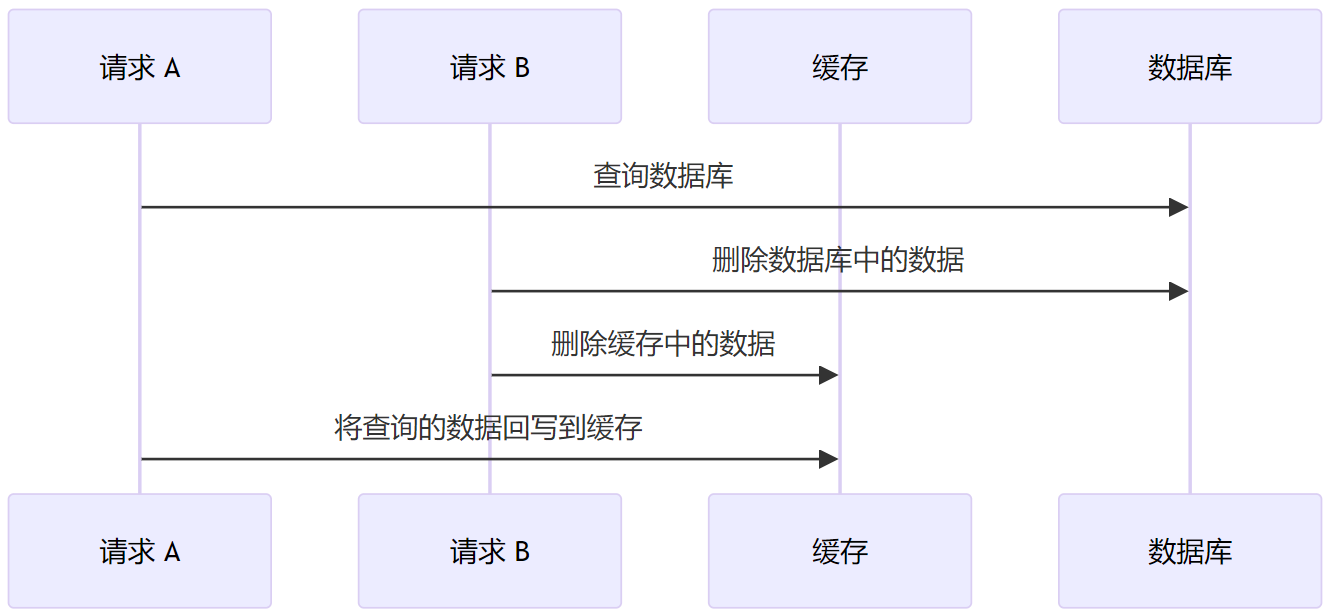
如果先删除缓存,考虑如下的时序,其实最终数据库没有数据,而缓存中却有。
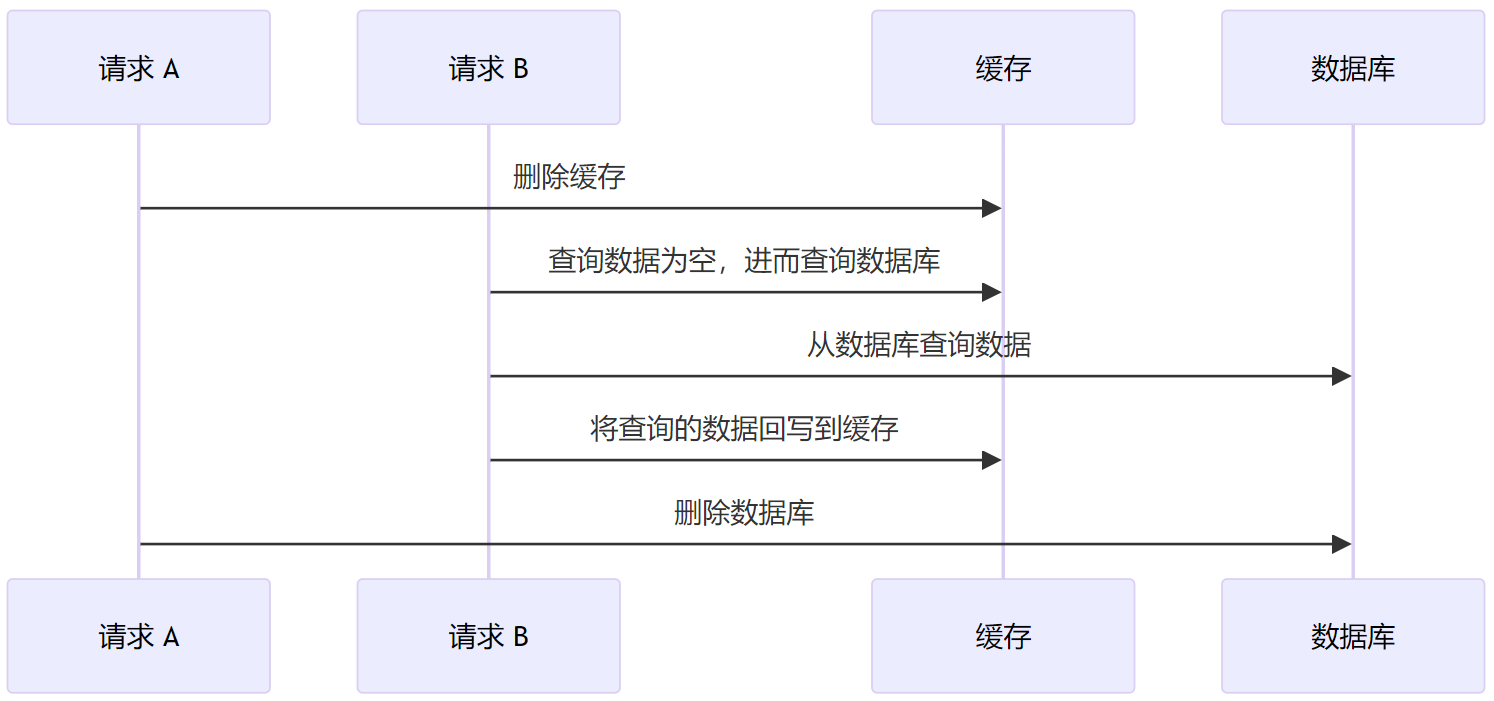
先删除数据库,后删除缓存
如果先删数据库,考虑如下的时序,最后也是数据库没有数据,而缓存中却有。
更新场景
我们再来看更新数据库的场景,这里就不止两种时序了,因为对于缓存中的数据,我们可以做更新,也可以做删除。
先更新缓存,后更新数据库
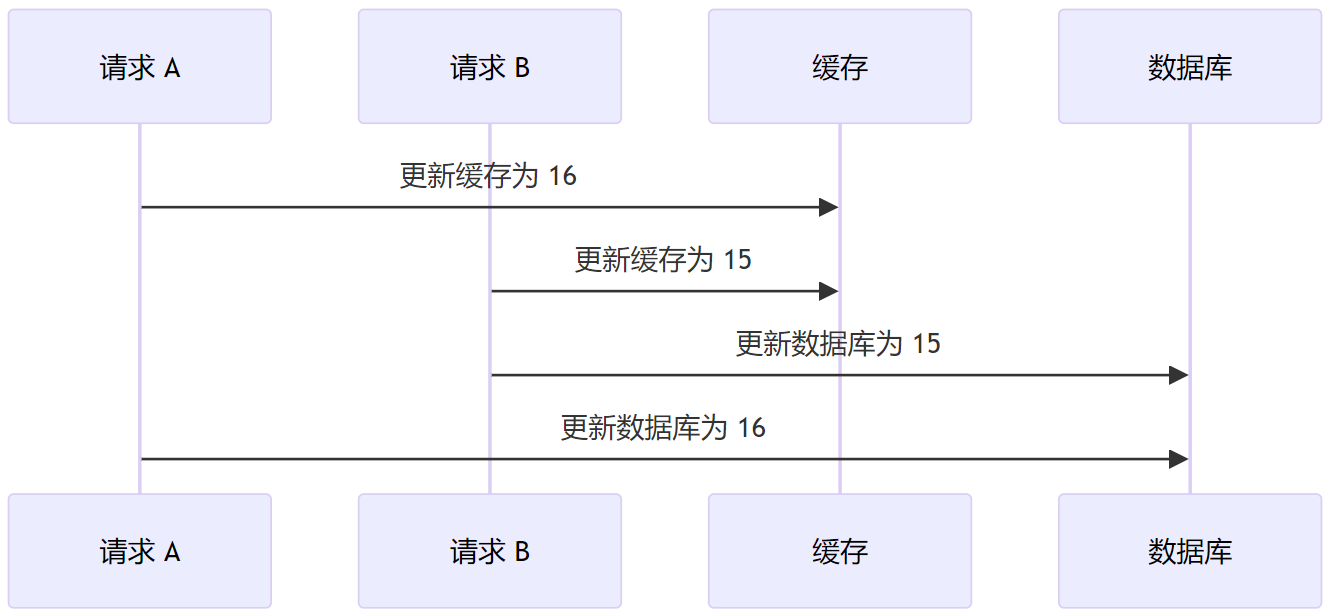
如果先更新缓存,后更新数据库,考虑如下的时序,最后缓存中数据为 15,而数据库数据为 16,这就出现了数据不一致的问题。
先更新数据库,后更新缓存
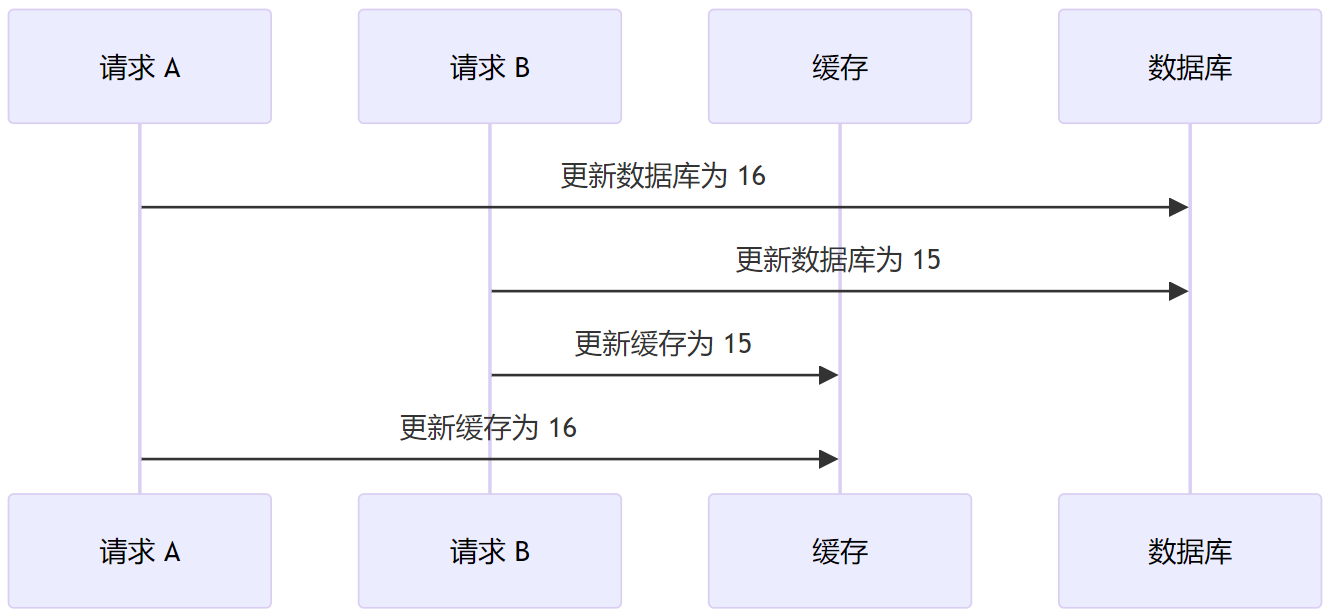
而如果先更新数据库,后更新缓存,考虑如下的时序,最后缓存中数据为 16,而数据库数据为 15,也出现了数据不一致的问题。
先删除缓存,后更新数据库
那么我们再考虑删除缓存呢?
如果先删除缓存,后更新数据库,考虑如下的时序,最后缓存中数据为 16,而数据库数据为 15,出现了数据不一致的问题。
你会发现这种情况和「先删除缓存,后删除数据库」是类似的。

先更新数据库,后删除缓存
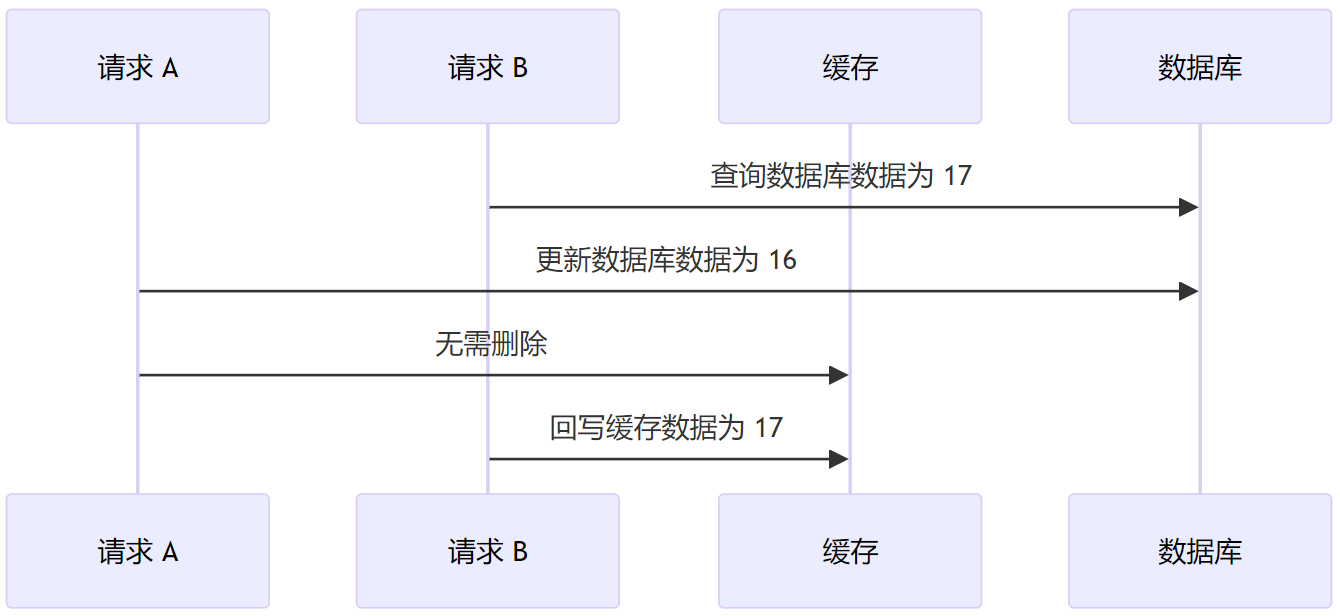
如果先更新数据库,后删除缓存,考虑如下的时序,最后缓存中数据为 17,而数据库数据为 16,也出现了数据不一致的问题。
你会发现这种情况和「先删除数据库,后删除缓存」也是类似的。
介绍了这么几种可能导致缓存和数据库数据不一致的情况,我们该如何解决呢?
数据一致性方案
首先还是要说明,我们不能够保证缓存和数据库数据的强一致性,只能保证最终一致性。
删除 or 更新
其次我们考虑一下,对缓存的操作,到底是删除还是更新。
放到缓存中的数据,很多时候可能不只是一个简单的字符串类型的值,还可能是一个大的 json 串,一个 map 类型等等。
举个例子,当我们需要通过缓存进行扣减库存的时候,可能需要从缓存中查出整个订单模型数据,把它进行反序列化之后,再解析出其中的库存字段,把它修改掉,然后序列化,最后再更新到缓存中。
这里更新缓存的动作,相比于直接删除缓存,操作过程比较的复杂,而且也容易出错,并且在数据库和缓存的一致性保证方面,删除缓存相比更新缓存要更可靠一些。
所以我们优先是考虑删除缓存而不是更新它。
先缓存 or 先数据库
那么在此基础上又有两种情况,先删除缓存再操作数据库,还是先操作数据库再删除缓存。
先操作数据库再删除缓存
通过前面场景的分析,我们也知道了,先操作数据库再删除缓存带来的一致性问题其实会更小一些,因为这种方案的不一致情况发生在 更新缓存的时间要超过更新数据库,这在大多数情况下是不现实的。
延迟双删
业界还有一种延迟双删的方案可以很好的解决 先删除缓存后操作数据库 的数据不一致的问题。
在先删除缓存后操作数据库的场景中,出现数据不一致的情况是后续的请求将数据库中的数据回写到了缓存中,所以我们可以在请求操作数据库之后,隔一段时间,保证后续的请求回写到缓存中后,当前请求再删除一次缓存。
时序图如下:
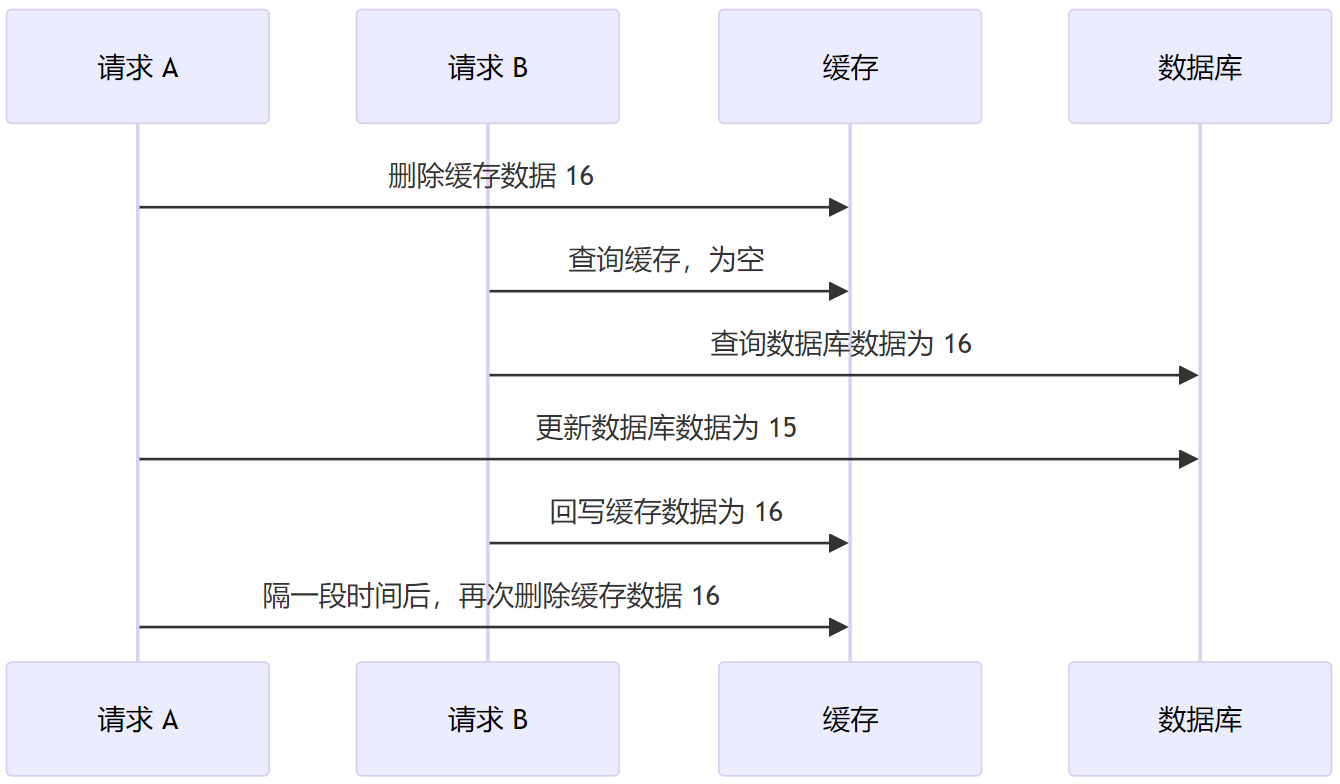
但是,如何保证请求 A 第二次删除缓存是在请求 B 回写缓存之后?这就需要对系统写缓存的时间做一个经验性的评估了。
最后,这种删除缓存的方案在并发很高的情况下,也是不建议使用的,因为一旦系统来了一个写请求,就会导致系统的缓存失效,从而导致缓存雪崩、击穿的问题,所以,业界用的最多的还是基于监听 binlog 做缓存异步更新的方案。
binlog 异步更新缓存
基于监听 binlog 做缓存异步更新的方案算是一个比较通用的业界流行的方案了。
一个简单的时序如下:
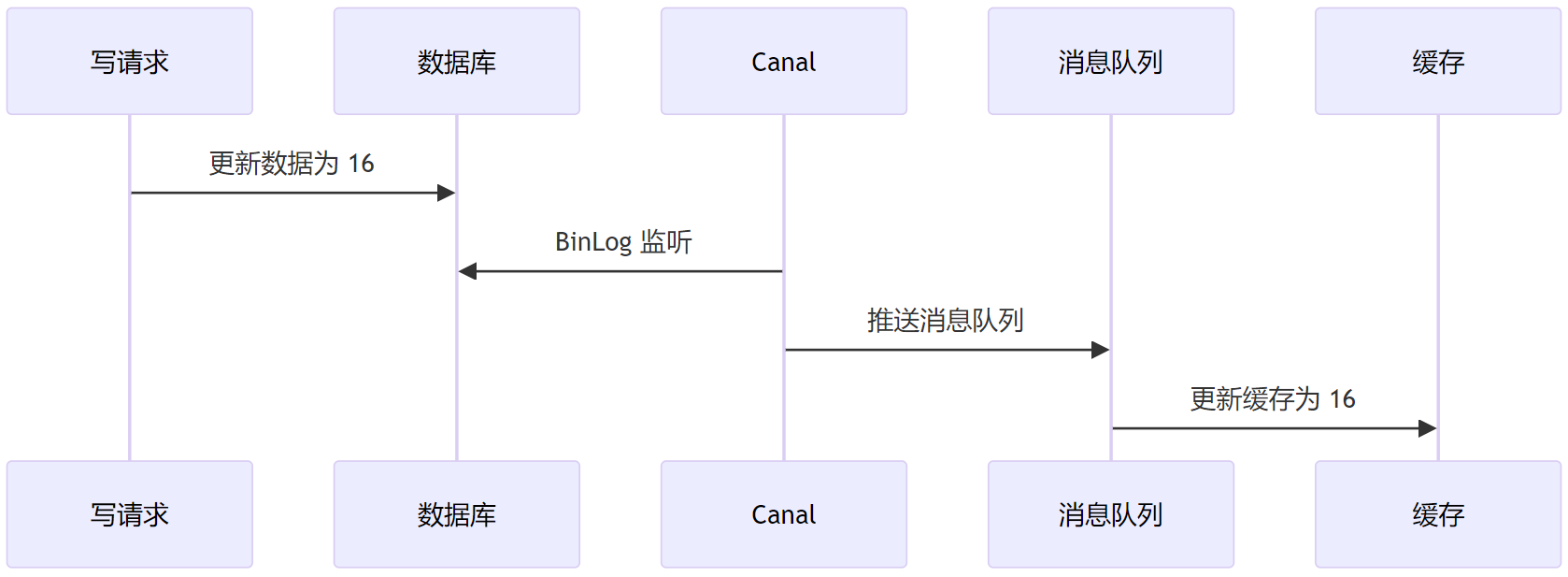
这种基于 binlog 的异步化方式可以让我们在编写业务代码时不必考虑更多的有关缓存的存储细节,将业务开发和如何保证数据一致性解耦。
其次,因为是异步更新,所以更新业务的性能是能够得到一定的提升的。
当然,也正因为引入了 Canal 和 MQ 中间件,所以你必须保证这些中间件的高可用,这就增加了系统运维的成本。
还有就是,引入了异步流程,也会导致整个缓存数据的更新链路会被拉长,尤其是 MQ 出现了消息堆积的情况,那么达到最终一致性的时间也会拉长,这就需要在业务层次去考虑是否可以容忍这种情况。
兜底策略
最后,其实我们之前也说过了,对每一个缓存的数据,我们都应该设置一个超时时间来做缓存和数据库数据的最终一致性的兜底。
总结
那么总的来说,缓存和数据库的一致性方案,基本上可行的就三种:
- 先更新数据库,后删除缓存
- 延迟双删
- binlog 异步更新缓存
那么我们该怎么选择呢?
对于并发不高、系统能够接受较长时间不一致的情况,可以直接使用第一种方案,即先更新数据库,后删除缓存,当然,为了避免极端情况下出现缓存删除失败导致的不一致情况,我们需要设置超时时间或者在查询接口增加对缓存的自动刷新,这样到时间之后,缓存才能进行自动更新。
而对于并发不高,但是系统无法容忍长时间不一致的情况,就可以选择第二种方案了,即延迟双删,比如我们对用户信息进行了缓存,如果对用户要进行冻结,那么此时一定要让缓存中的数据失效,所以,我们进行延迟双删来保证缓存数据一定被删除。
最后,在一些高并发或者秒杀的场景下,删除缓存是万万不行的,一旦删除缓存就可能导致数据库的击穿,所以我们可以采用监听 binlog 异步更新缓存的方案。